

BulkOperation类的子类BulkOperationPacked,提供了很多对整数(integers)的压缩存储方法,其压缩存储过程其实就是对数据进行编码,将每一个整数(long或者int)编码为固定大小进行存储,大小取决于最大的那个值所需要的bit位个数。优点是减少了存储空间,并且对编码后的数据能够提供随机访问的功能。
1 | 例如有以下的数据{1,1,1,0,2,2, 0, 0},二进制的表示为{01, 01, 01, 0, 10, 10, 0, 0},存储需要32个字节大小的空间。数据中最大的值是2,需要2个bit位即可表示,所以其他数据统一用2个bit位固定大小来表示,编码后需要的空间如下图: |
图1:
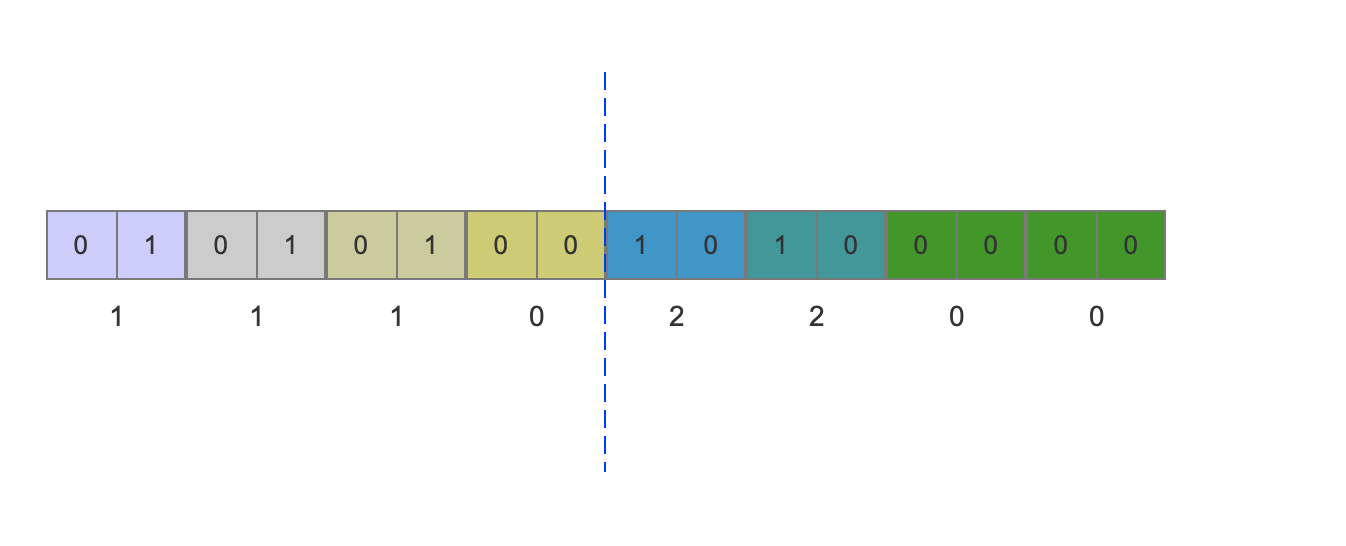
如上图所示,编码后只需要2个字节的空间大小。
encode 源码解析
https://github.com/luxugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/util/packed/BulkOperationPacked.java 中给出了详细的注释,根据不同的bitsPerValue(最大值需要的bit位个数),BulkOperationPacked有几十个子类,但是编码操作都是调用了父类BulkOperationPacked的encode方法,仅仅是部分BulkOperationPacked子类的decode方法不同一共有四种encode方法:
- long[]数组编码至byte[]数组
- int[]数组编码至byte[]数组
- long[]数组编码至long[]数组
- int[]数组编码至long[]数组
在下面的代码中,挑选了其中一种encode方法,即将 long[]数组编码至byte[]数组,出于仅仅对encode逻辑的介绍,所以简化了部分代码,比如iterations,byteValueCount变量。这些变量不影响对encode过程的理解。下面的代码大家可以直接运行测试。
1 | public class Encode { |
输出的结果是 84, -96。
decode 源码解析
全解码
不同的BulkOperationPacked子类有着不同的decode方法,解码的方法不尽相同,在Lucene7.5.0版本中,共有14种解码方法,尽管有这么多,但是逻辑都是大同小异。由于在上文中我们设置的bitPerValue的值为2,所以我们就介绍对应的decode方法。
1 | public class Decode { |
随机解码(随机访问)
上面的decode()方法对所有的数据,按照在byte[]数组中的顺序依次解码,下面介绍的就是这种编码带有的随机访问(随机解码)的功能。
下面的get()方法在DirectReader类中实现。根据bitsPerValue的值(encode阶段,固定大小的bit位数),本篇博客中仅列出bitsPerValue值为2的解码方法,对应上文的encode方法。更具体的注释请查看GitHub:https://github.com/luxugang/Lucene-7.5.0/blob/master/solr-7.5.0/lucene/core/src/java/org/apache/lucene/util/packed/DirectReader.java 。
1 | 1. public long get(long index) { |
例子(随机访问)
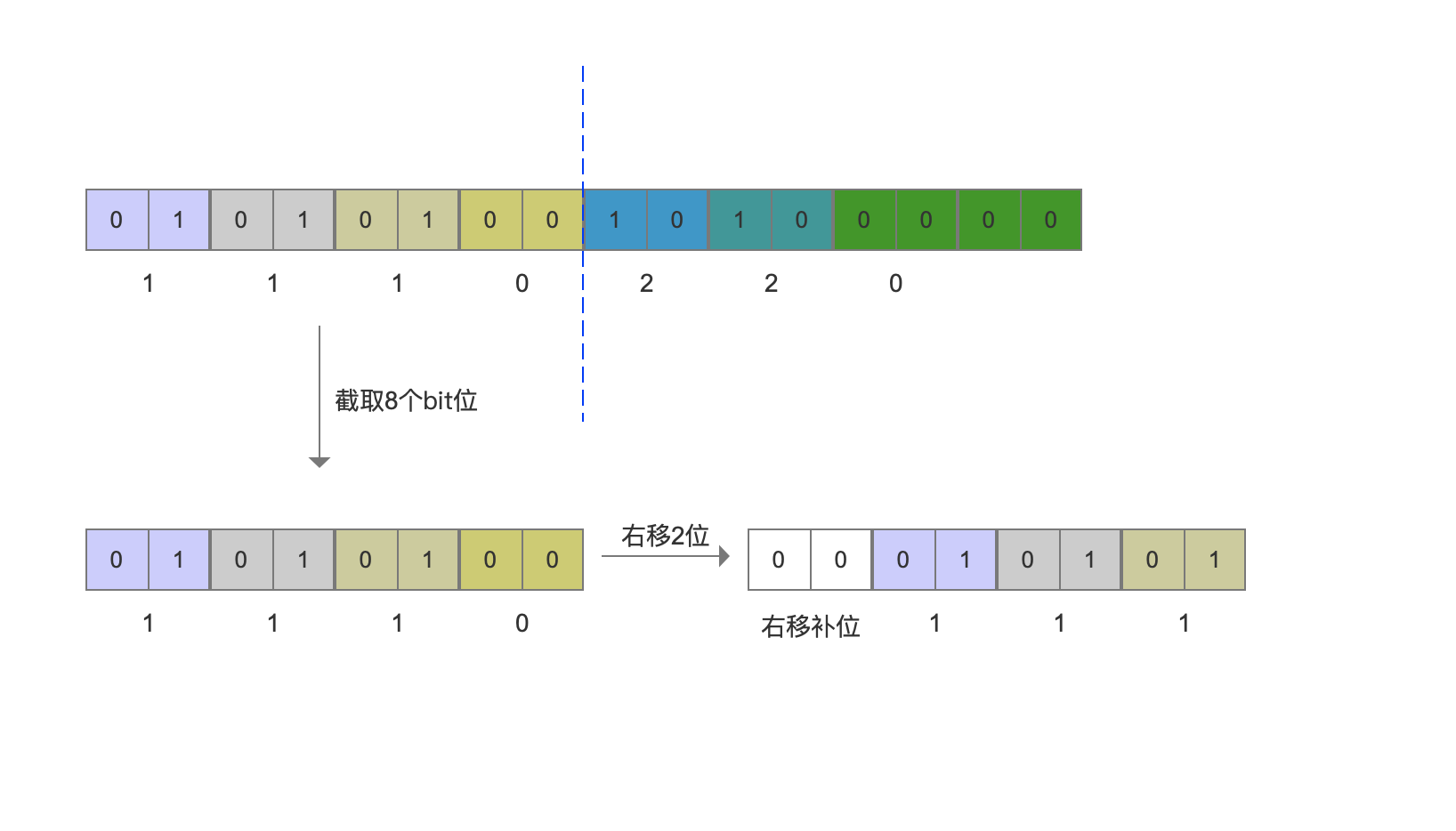
编码后的值如下图所示:
图1:
取出原数组中下标值(index)为2的数组元素
根据decode中第5行代码,我们先求出shift的值为 2。截取上图中部分字节数据,大小为 index >> 2, 即截取8个bit位,然后根据shift的值执行无符号右移操作(第7行代码),如下图:
图2:
接着根据第7行代码与0x3执行与操作,如下图:
图3:
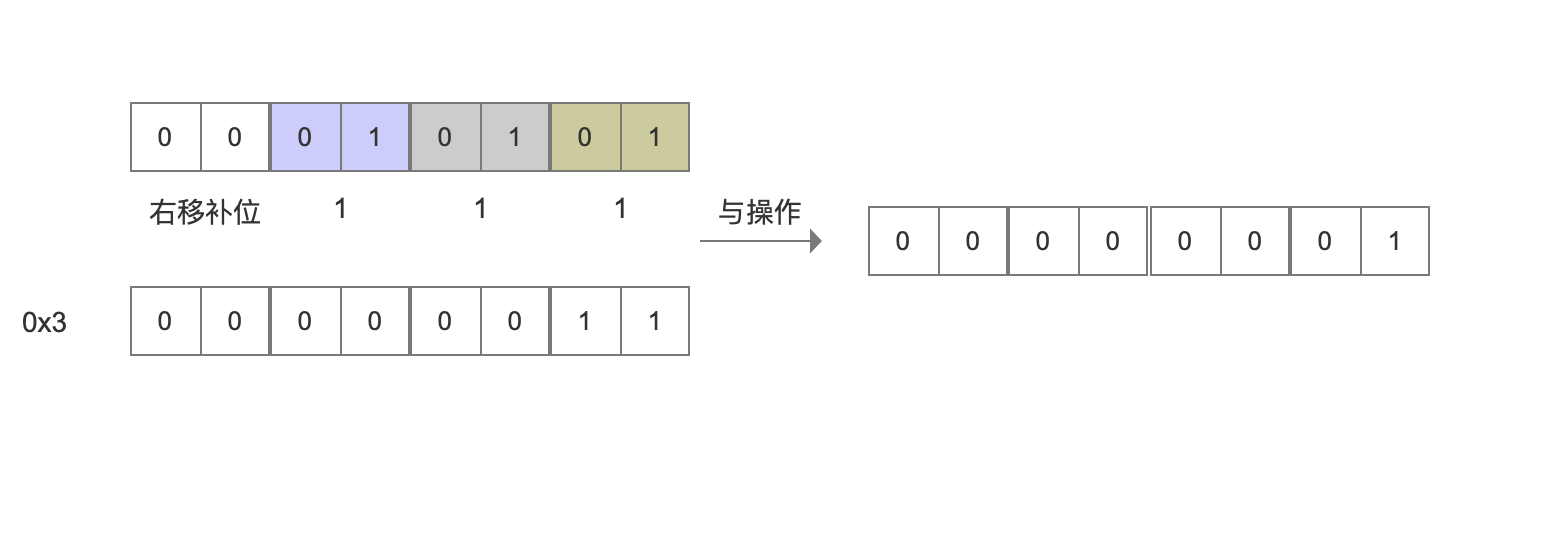
从上面的解码过程可以看出,这种编码方式可以实现随机访问功能。
在Lucene中的应用
在DocValues中,有着广泛的应用,例如在SortDocValue中,用来存放ordMap[]数组的元素值,ordMap[]的概念会在后面介绍SortedDocValuesWriter类时候介绍。
结语
本篇博客介绍了使用BulkOperationPacked类实现对整数(long或者int)进行压缩存储,与去重编码相比,优点在于在解码时性能更高,并且能实现随机访问,在去重编码中,由于使用了差值存储,所以做不到随机访问。缺点在于当数据中出现较大的值时,压缩比就不如去重编码了。
点击下载Markdown文件